Semantic Alignment in Hyperbolic Space for Open-Vocabulary Semantic Segmentation
Hoang M. Truong, Hai Nguyen-Truong, Dang Huynh
CVPR Workshop 2026
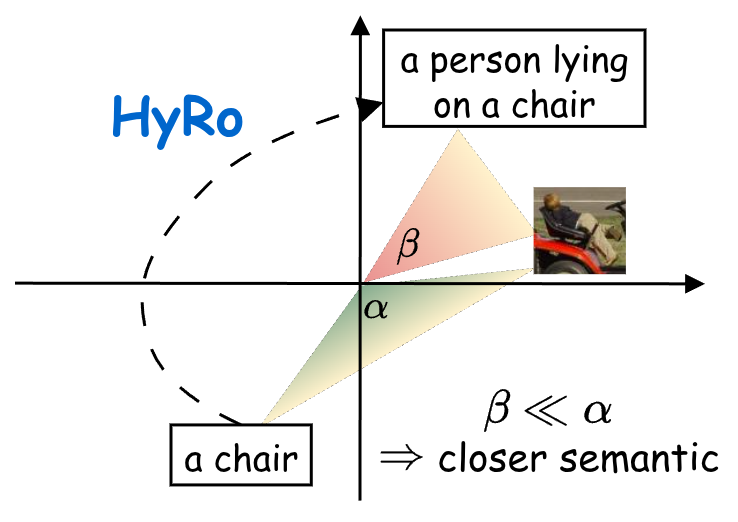
Summary We tackle semantic misalignment in open-vocabulary semantic segmentation by proposing (1) HyRo, a hyperbolic rotation module that refines angular relationships in the Poincaré ball while preserving hierarchical structure, and (2) a hyperbolic fine-tuning framework that decouples semantic alignment (angle) from hierarchical alignment (radius), enabling more accurate pixel-level predictions and state-of-the-art performance.

